EgoProc Benchmark
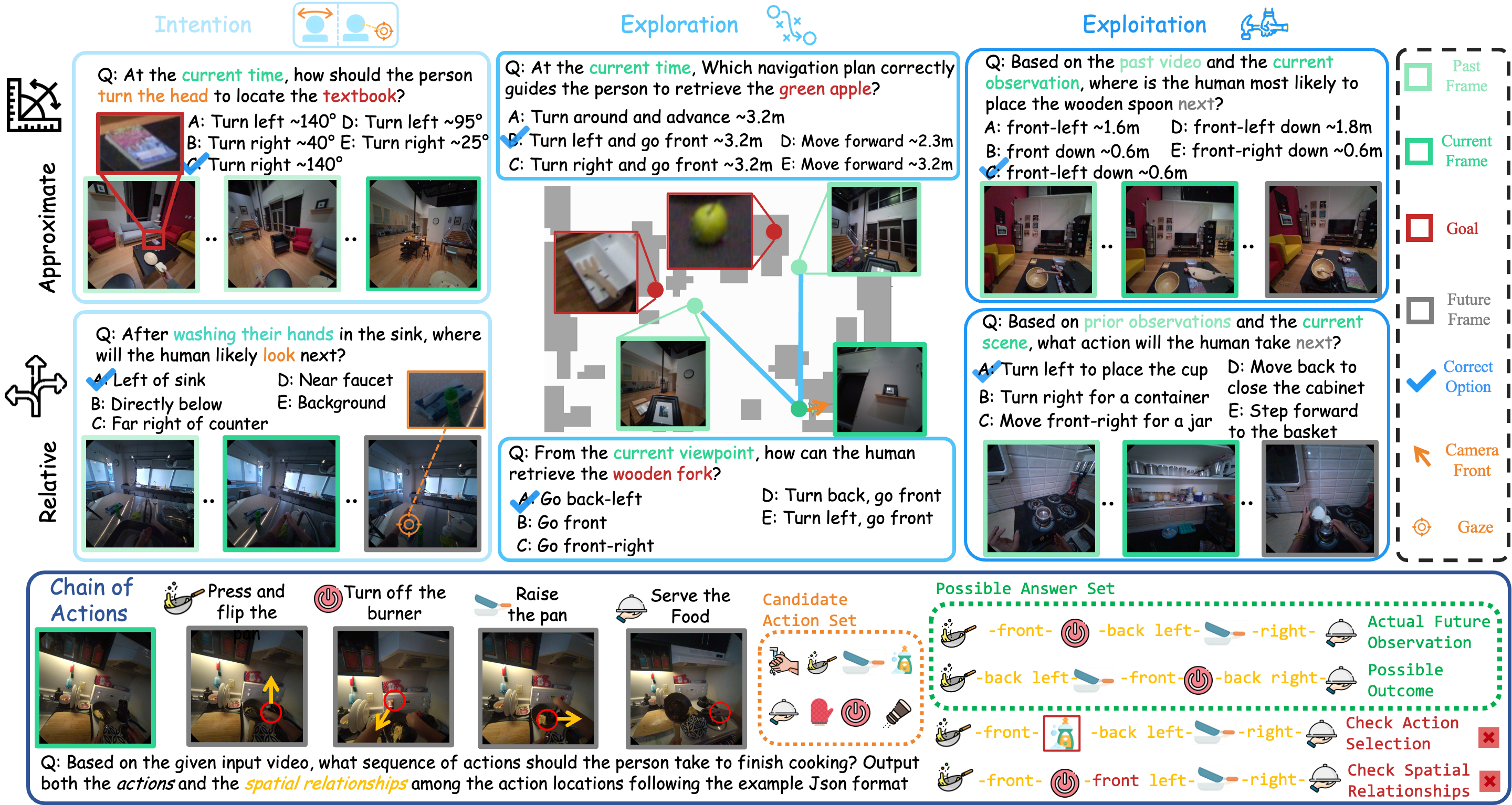
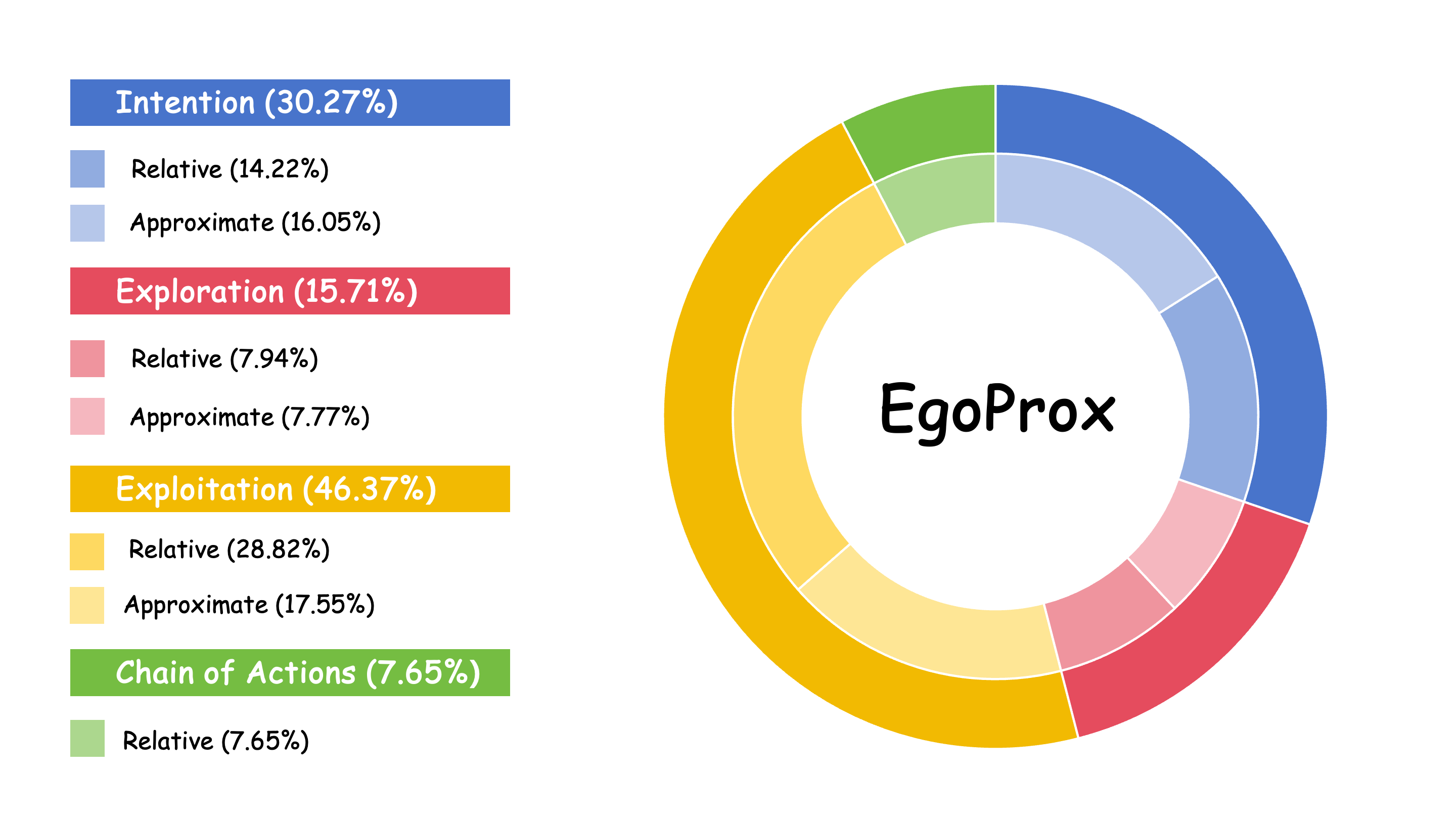
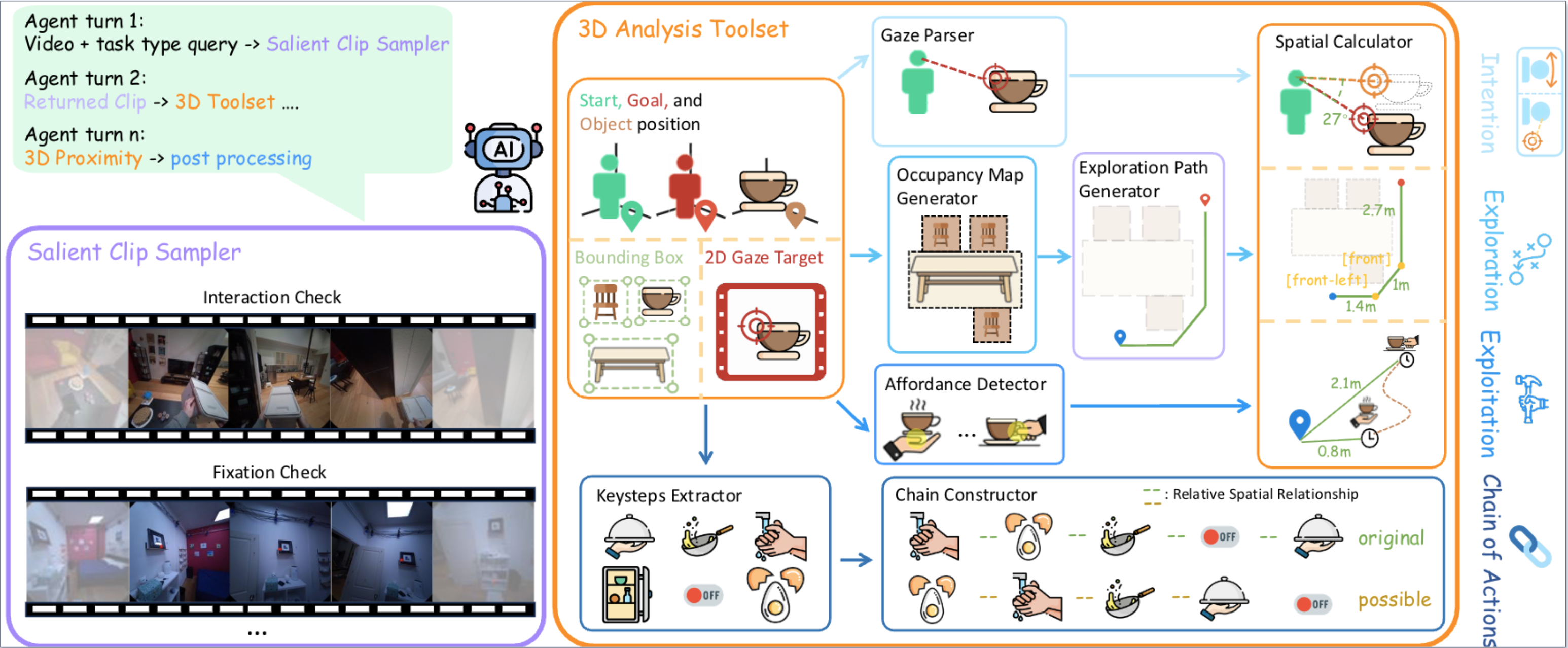
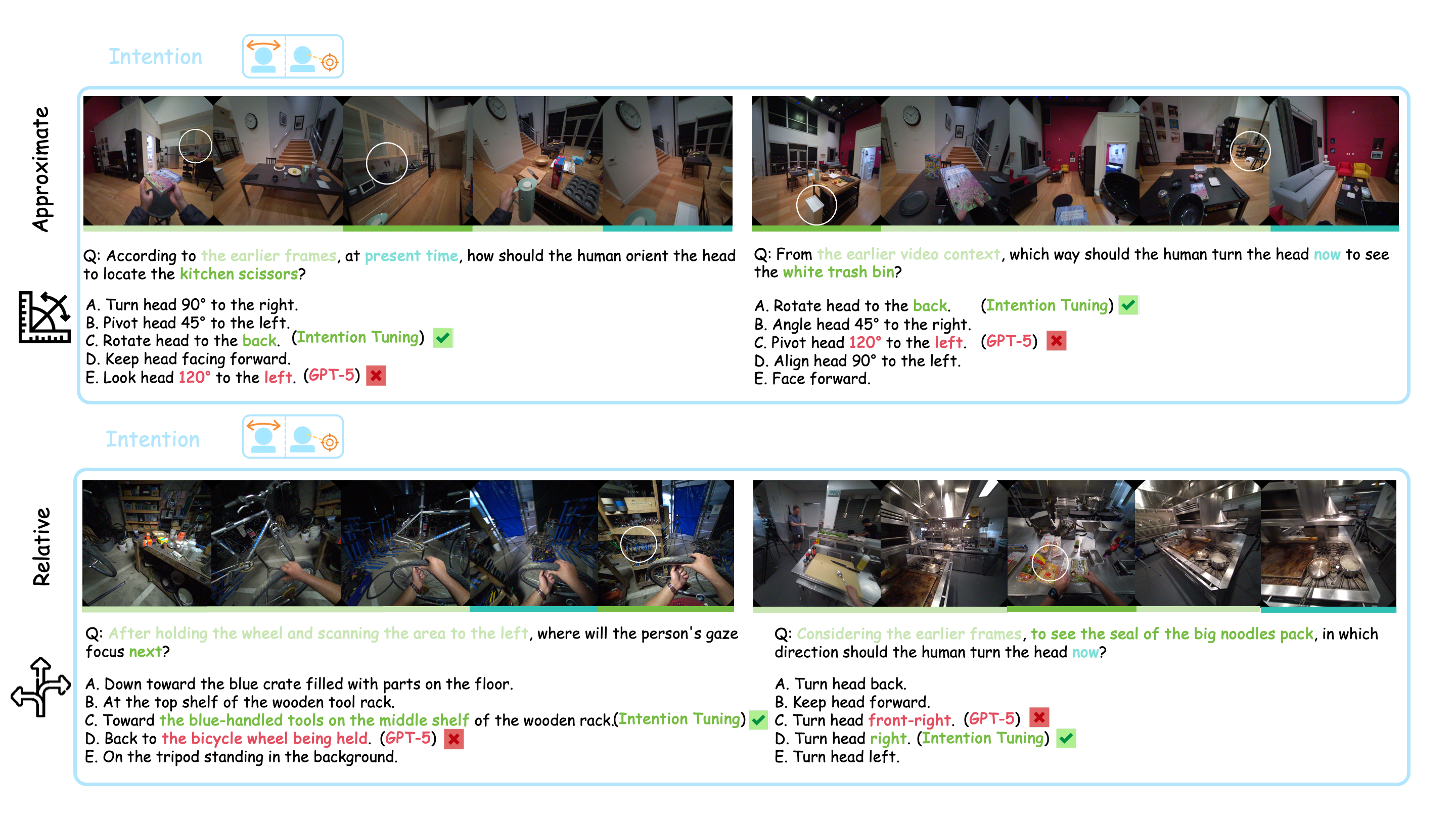
We propose EgoProx, the first benchmark designed to evaluate whether MLLMs can reason 3D perception–action coupling from an egocentric point-of-view, with four tasks organized along a cognitive hierarchy: Intention, Exploration, Exploitation, and Chain of Actions.